
Web Scraping for Beginners using Scrapy python
Learn how to scrape your first website and get data from it using python library Scrapy.


In my previous article, I talked about how to install Scrapy and create your first project. Check it out here.
Project Structure
So when you will create a new Scrapy project, you will see a bunch of files and folders. Let's open the project in IDE. I am going to use VSCode but you can go for any IDE of your choice.
First, I will open the command line by typing cmd in the top bar.
In the command line, I will run "code ." it will fire up VSCode in the working directory.
code .
Now let's take a look at all the files and folders that were automatically created by Scrapy.
There are a lot of files containing code so don't overwhelm yourself. We will only focus on the folder named spiders. In Scrapy there are spiders for each website you want to scrape. So to scrape our first website we would need to create a spider.
Spiders
You can create multiple spiders in one project. Spiders are python code files that run and return the scraped data. Creating a new spider is easy and takes two steps. First, you have to navigate to the spiders folder in the command line. For that, go to the terminal and use "cd" command in windows or alternate in mac.
In my VSCode I will open a new terminal and run the command,
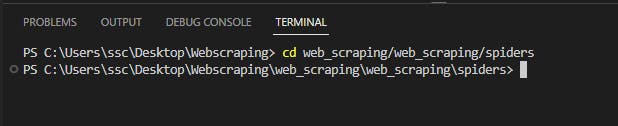
Note: folder names could be different for you depending on your project naming.
Once in the spiders folder, we will create a new spider to scrape our first website. I am gonna choose a simple webpage, click here to see(Go to the page and explore its source file, see how the HTML code is written). To create a spider you need to think of a name for that spider and provide a URL for the website. I am simply gonna call my spider "ietf". Now I will run the below command in my terminal.
Scrapy genspider <spidername> <URL>
Scrapy genspider ietf https://pythonscraping.com/
If everything worked fine, you would see a new python file created in the spiders folder. Go ahead and explore it.
Below is the code that's in the ietf.py file.
import scrapy
class IetfSpider(scrapy.Spider):
name = 'ietf'
allowed_domains = ['pythonscraping.com']
start_urls = ['http://pythonscraping.com/']
def parse(self, response):
pass
Now, I am going to make some changes and explain it all to you.
import scrapy
class IetfSpider(scrapy.Spider):
name = 'ietf'
allowed_domains = ['pythonscraping.com']
start_urls = ['https://pythonscraping.com/linkedin/ietf.html']
def parse(self, response):
return {
"title": response.xpath("//span[@class='title']/text()").get(),
}
Note: To execute the code you need to run the following command in the terminal. Scrapy runspider ietf.py
Don't worry it's not as messed up as it seems, there's a pretty simple explanation here for what I did. First I changed the start_urls with the URL of the page I want to scrape. Then I tweaked the parse function to read the title of the page from its HTML code.
My parse function returns a dictionary that keeps the title of the page I parsed. Inside the function I have used a built-in function response.xpath(). What it does is it pulls data from the HTML code of the given URL. xpath takes some sort of rule as its parameter. This rule defines what data to pull based on the HTML tags.
Understanding response.xpath
Let's understand a few notations,
| Symbol | Meaning |
| // | anywhere nested in the tag |
| / | immediate children |
| * | everything |
| @ | value of |
| text() | returns text inside the tag |
Now let's understand the rule,
('//span[@class='title']/text()').get()
It means any span tag whose class attribute value is "title" go inside of it and fetch the text.
Now let's scrape some more information,
import scrapy
class IetfSpider(scrapy.Spider):
name = 'ietf'
allowed_domains = ['pythonscraping.com']
start_urls = ['https://pythonscraping.com/linkedin/ietf.html']
def parse(self, response):
return {
"title": response.xpath("//span[@class='title']/text()").get(),
"author": response.xpath("//span[@class='author-name']/text()").get(),
"meta_author" : response.xpath("//meta[@name = 'DC.Creator']/@content").get(),
"text": response.xpath("//div/span[@class = 'subheading']/text()").getall()
}
Note: To execute the code you need to run the following command in the terminal. Scrapy runspider ietf.py
I highly encourage you to navigate to the webpage we are scraping and take a look at its HTML code.
Author's Name:
The author's name was given in two different places and I scraped it from both sources for demonstration purposes.
('//span[@class='author-name']/text()').get()
Find a span tag whose class attribute value is 'author-name', go inside it and take the text out of it.
('//meta[@name = 'DC.Creator']/@content').get()
Find a meta tag whose name attribute value is 'DC.Creator' and return the value of its content attribute.
SubHeadings and paragraphs:
('//div/span[@class = 'subheading']/text()').getall()
The code above means, find a div tag whose immediate child is a span tag with class attribute value as 'subheading', go inside that span tag and get the text. The getall() returns all values that match the description. So we will get a list of subheadings.
("//div[@class = 'text']/text()").getall()
This bit says, find a div whose class attribute value is 'text' and get all the text that is its immediate child. Hence we will get all the paragraphs.
If I were to add another '/' before text(), I would be getting all the subheadings and their paragraph text in order. Let's see how.
("//div[@class = 'text']//text()").getall()
Go inside that particular div and extract all text nested anywhere inside the div. This gives us the text in span tags(subheadings) and the text directly inside the div tag(the paragraphs).
So that's it for the basics of scrapy. Go through the article again if some pieces don't fit well yet and also see the HTML code of the webpage we are scraping.
Here's the Github Repository for the code I did.
See you next time!!